Large language models (LLMs) training has predominantly relied on the accumulation of vast datasets. Recent observations suggest that even a modest quantity of high-quality diverse data can significantly enhance the instruction following capacity of LLMs. Previously, data quality control relied heavily on manual selection processes. This approach, while being commonly used, rendered scalability challenges due to the substantial labor costs. Recent advancements have seen automated low-quality data filters, such as perplexity filters and de-duplication filters. However, their effectiveness in data quality control in more complex environments remains to be explored, where data are spread across silos and locations in different formats and difficult to find.
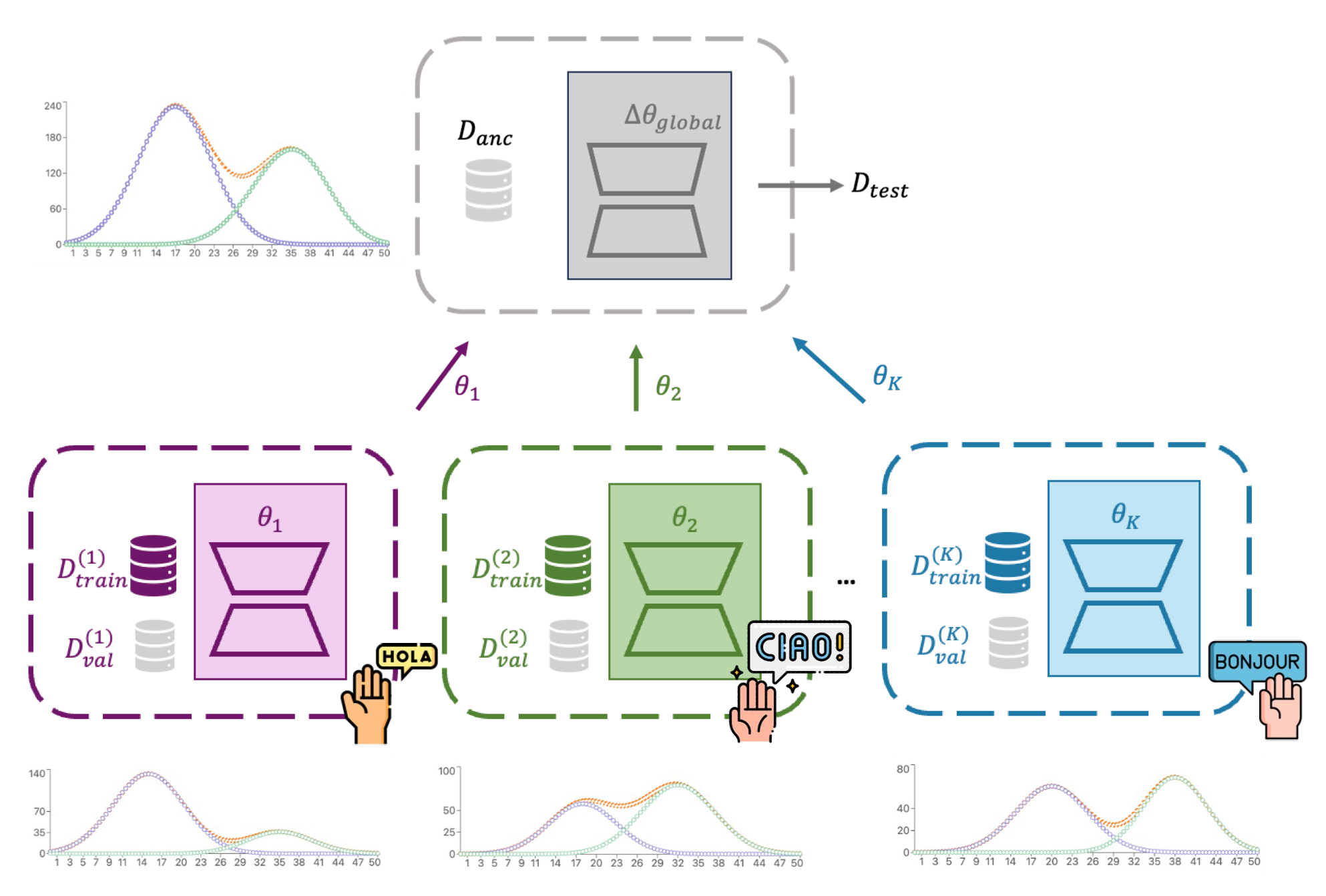
Collaborative training techniques, such as model merging and federated learning, are common paradigms for addressing data-sharing constraints and GDPR compliance. However, data quality control for private data is even more challenging if users are in charge of manually filtering data. We summarize here the two unique challenges: (1) Quality Heterogeneity Some clients may possess a higher proportion of low-quality data compared to others, thus we should not select data from all clients with a fixed selection ratio. (2) Domain Heterogeneity Different data silos may come from different vertical domains, for example, in the multilingual setting, different languages have different quality standards that are never unified.
In this paper, we propose CLUES (collaborative learning under exemplar scoring), an automated high-quality data selection method for collaborative fine-tuning of Large Language Models (LLMs), showcasing notable performance improvements in mixed-quality data environments from different private domain data. In these domains, private LLM vendors are supposed to build their specialized applications based on open-source LLMs using their own private data, which represent specialized domains with significant private (e.g., patient records) and public data (e.g., scientific papers). By tracing the training dynamics of each training sample, we leverage public dataset to define an anchor dataset and compute the influence of each training sample on the anchor dataset, and set a global threshold to provide effective collaborative quality controls compared with traditional local data quality selection methods in the following aspects: (1) General: Our method is a general pipeline to improve the generalization performance for LLM fine-tuning. It has an interpretation in terms of bi-level optimization with inner optimization in the client side and outer optimization in the server side to minimize the loss on the anchor dataset. (2) Collaborative: Our method is a collaborative fine-tuning paradigm that can be seamlessly integrated into existing model merging and federated learning frameworks, where the modification occurs on the server side only to incorporate data selection. (3) Scalable: We only employ an approximation to solve the bi-level optimization, which makes it scalable to LLMs.
We evaluate our proposed method on medical, multilingual and financial Question Answering (QA) datasets, demonstrating significant improvements of up to 67.3% on challenging medical and financial QA datasets, highlighting the effectiveness of our proposed method. Through extensive analyses, we demonstrate the significant impact of leveraging training dynamics on the collaborative data quality control of LLMs.
@inproceedings{
zhao2024clues,
title={{CLUES}: Collaborative Private-domain High-quality Data Selection for {LLM}s via Training Dynamics},
author={Wanru Zhao and Hongxiang Fan and Shell Xu Hu and Wangchunshu Zhou and Nicholas Donald Lane},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
}

